
The Hedera mirror node software, during its alpha phase of development, was run by Hedera, exchanges, and other third-parties (such as network explorers like HashScan, Hashlog, & DragonGlass, and auditing tools like Armanino’s TrustExplorer). These third parties had express permission to access real-time and historical network data buckets in Google Cloud Platform (GCP) and Amazon Web Services (AWS) in order to run their services.
Starting today, we’re happy to announce that everyone now has access to real-time and historical raw data files for the Hedera testnet and mainnet via public AWS and GCP buckets. Early access users experienced the brunt of early mirror node software — they provided Hedera with invaluable feedback, which brought us to beta and public availability today.
Access to these buckets enables developers to configure and deploy their very own beta Hedera mirror node, as well as analyze network data using a brand-new Hedera-ETL software tool that works with Google BigQuery.
In addition, everyone now has the ability to independently verify the authenticity of Hedera mainnet and testnet data. This can all be done without needing any permission from Hedera — an important step in our path towards a fully decentralized network.
Found below is information on and setup instructions for:
- Open source mirror node (beta) software, including one-click deploy on GCP
- Real-time and historical network data from buckets in GCP & AWS
- Hedera-ETL (extract, transform, load) scripts for use with Google BigQuery
Open source mirror node (beta) & one-click deploy in GCP
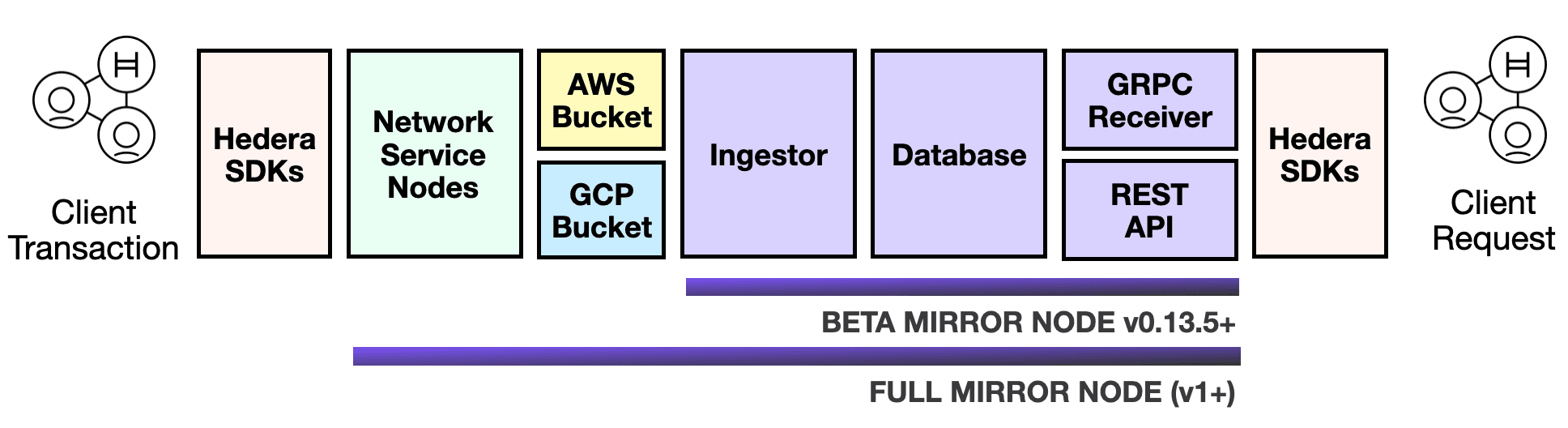
The beta Hedera Mirror Node software exposes Hedera network transaction records and account balances generated by the Hedera mainnet or testnet via a REST & gRPC API.
Found below are a few documented ways in which anyone can deploy and configure a Hedera mirror node:
- One-click deploy from the GCP Marketplace (easiest)
- Using Docker
- Using Helm and Kubernetes
- Using Ansible, Ubuntu, & Docker in GCP
Beta mirror nodes vs full mirror nodes
The beta version of the Hedera mirror node software requires the use of public buckets in GCP or AWS to retrieve network data. These buckets record every transaction record, balance (every account and its balance) and events coming from every node on the Hedera mainnet and testnet.
At a high level, the mirror node software, prior to its ingestion of data to the mirror node database, validates every file and signature from AWS or GCP buckets to ensure their validity. It does so by checking:
- That a sufficient number of nodes have signed identical files with matching hashes.
- The chain hash to ensure no files are missing.
- The address book, all the way back to its genesis.
Technical details on beta mirror nodes can be found in the Hedera documentation.
In the future, the full Hedera mirror node software (v1) will maintain the consensus state of the network and its historical transactions (or a defined subset thereof), in addition to always watching the network for new transactions. By maintaining the consensus state, mirror nodes will be able to record and be queried for mathematically verifiable state proofs for any transaction.
A full mirror node will be capable of doing everything a regular network node can do, sans accepting Hedera API transactions, creating events, or influencing consensus. Full mirror nodes will primarily be used to provide value-added services such as audit support, access to historical data, transaction analytics, and more.
Availability of mainnet & testnet data in GCP & AWS buckets
With the availability of network data buckets in AWS and GCP, anyone can integrate both real-time and historical network data directly into their business applications — whether it’s for audit support, transaction analytics, visibility services, security threat modeling, data monetization services, or something entirely different.
The network data stored in GCP and AWS buckets are configured for “requester pays”. This means the beta mirror node operator is responsible for the operational costs and egress from the buckets, but isn’t required to pay a fee for the data itself.
For instruction on how to access these buckets, check out the documentation.
Analyzing Hedera network data with the Hedera-ETL tool
The Hedera team has partnered with the blockchain ETL project to create Hedera-ETL. Hedera-ETL populates a BigQuery dataset with transactions and records generated by the Hedera mainnet or testnet, pulled from public AWS and GCP buckets.
The ETL tool uses the same ingestion software as the mirror node software but, instead of publishing the data to the mirror node database, it’s pushed straight into Google BigQuery. The ETL works like this:
- Extract: Stream of transactions (and records) are ingested from a GCP PubSub topic
- Transform: Filters for important fields, formats data types, etc
- Load: Streaming insert into BigQuery dataset
Like any typical batch processing system, Hedera-ETL is most suitable for applications that want to run big, scalable queries and analysis on Hedera network data. For applications that need real-time responsiveness, an aforementioned traditional mirror node would be more suitable. Here are some example queries to help get you started:
Which accounts were newly created in the month of March 2020 and at what exact time?

select consensusTimestampTruncated, entity
from hedera-etl.mainnet.transactions
where transactionType = 11 -- CRYPTOCREATEACCOUNT
and consensusTimestampTruncated > TIMESTAMP_SUB(TIMESTAMP "2020-03-31 23:59:59 UTC", INTERVAL 31 DAY)
and consensusTimestampTruncated < TIMESTAMP "2020-03-31 23:59:59 UTC"
Which consensus service submit-message transactions were successfully processed on April 1st, 2020?
select *
from hedera-etl.mainnet.transactions
where
transactionType = 27 -- CONSENSUSSUBMITMESSAGE
and transactionRecord.receipt.status = "SUCCESS"
and consensusTimestampTruncated > TIMESTAMP_SUB(TIMESTAMP "2020-04-01 23:59:59 UTC", INTERVAL 1 DAY)
and consensusTimestampTruncated < TIMESTAMP "2020-04-01 23:59:59 UTC"


