
AdsDax is an end-to-end advertising platform that leverages the power of Hedera Hashgraph to tackle some of the fundamental problems of the advertising industry. It is estimated that for every $3 spent on digital advertising as much as $1 is wasted on fraudulent activity [AdAge]. Factoring in other inefficiencies such as money spent on Agencies, Trade Desks and middlemen, it’s estimated that only a quarter of ad spend reaches actual users [AdWeek], with direct and indirect losses estimated to be around $30bn this year [The Drum].
While those stats show the challenges facing Advertisers investing in digital advertising, it’s important to also note the impact on users. Privacy concerns, bloated web pages and increased load times are leading to a massive increase in the adoption of ad blocking [GlobalWebIndex]. It is clear that the current trends are unsustainable, and something needs to change.
Enter AdsDax
Under the guise of its parent company, Yamgo Ltd., AdsDax and its team have been involved in the advertising sector for several years, adapting to changes in where and how users consume content. Having first-hand experience of the problems facing the industry, we began exploring the potential of distributed ledger technology in 2017, with the first prototypes being developed mid-2018.
Since that time we have completed several case studies with industry partners such as Isobar, Group M and Havas Media who share our vision of creating a fairer, more equitable advertising ecosystem using the power of decentralized, immutable trust.
Aims of AdsDax
Through the use of distributed ledger technology, AdsDax aims to improve the advertising ecosystem with the following goals:
- The reduction of fraud and wasted ad spend – By combining our existing AdShield technology with the immutable nature of decentralised ledgers, we aim to reduce occurrences of fraudulent activity, non-viewable advertising, discrepancies between advertising partners and also reduce the amount of money diverted to ad-tech providers.
- Fairness for Publishers – By utilising DLT our goal is to cherish and value Publishers by ensuring they maintain larger a share of the revenue generated by campaigns shown to their audience, and paying them in a fast and efficient manner as opposed to the 30-90 days or sometimes even longer delays they currently face.
- Fairness for Users – Our goal for users is to finally include them in the advertising process, allowing them to specify what (if any) data they wish to share, whom they wish to share it with, and compensate them for their time and attention when adverts are shown.
Whilst we have made great strides in progressing towards this goal, our current platform is merely the foundation upon which the full vision will hopefully be achieved. After Hedera Hashgraph opened publicly with the Open Access event on 16th September, we heard from a lot of people who were eager to sign up and start earning. Whilst we aren’t quite ready for users to sign up yet, I’d just like to assure everyone that we are still hard at work building the tools to do so.
How AdsDax works
If you have seen any of the press releases we have issued recently, you may be aware that AdsDax processes a lot of transactions. At the time of writing we have currently processed just over 16m transactions on the Hedera Hashgraph mainnet. What may not be clear however is that due to the way we are currently processing events, this equates to over 150m payable events on the AdsDax platform.
Of the data we have recorded on the mainnet so far, the peak activity we have managed to pass to the network consists of around 250 transactions per second, which equates to over 2200 payable ad events per second. At this speed and scale, it becomes almost impossible to use a single account to process all of the data. So we began asking ourselves, how can we guarantee that we will not generate a transaction collision? It is for this reason we have opted to use message queues.
How do message queues work?
When tracking our payable event data, we have the potential to track the event both when the event is triggered on the user’s device and when the event data is received and validated by the AdsDax platform. Both of these have their own issues however:
- If you are tracking on the device, how do you ensure your private keys aren’t revealed? Or if you pre-sign transactions, how do you know some nefarious entity won’t just submit them directly to the network (also, please note that our implementation pre-dates the Hedera Javascript SDK)?
- If you track once the event has been validated, how do you avoid transaction collisions? Do you need to generate hundreds or thousands of accounts? What is the impact of your application being delayed while waiting for a network response, or checking for a receipt or record? How do you recover if the transaction failed or the network is unavailable?
Message queues work by having a producer (in this case our tracking application) create a message with some sort of payload (in this case, payable event data), which it then submits to a topic (in our case, imaginatively called “events”). This topic can have multiple consumers which ingest the message and process the payload, with the exact process depending on the logic of the application.
Using a message queue has several advantages for us:
- If messages cannot be ingested straight away, they can be stored if necessary. This helps to handle both spikes in traffic and any issues that delay messages being processed such as downtime or network connection issues.
- Messages can be language/environment agnostic, with our messages produced via our PHP-based tracking platform but processed with our Go-based consumer.
- We gain some security benefits as we limit distribution of our private keys.
- Any failure in our ability to transact on the Hedera Hashgraph network is isolated away from our existing tracking platform.
- We have more granular control over separate processes, and can more accurately target resources where they are needed. For example, we can add more capacity to record checking versus submitting transactions.
How AdsDax tracking works
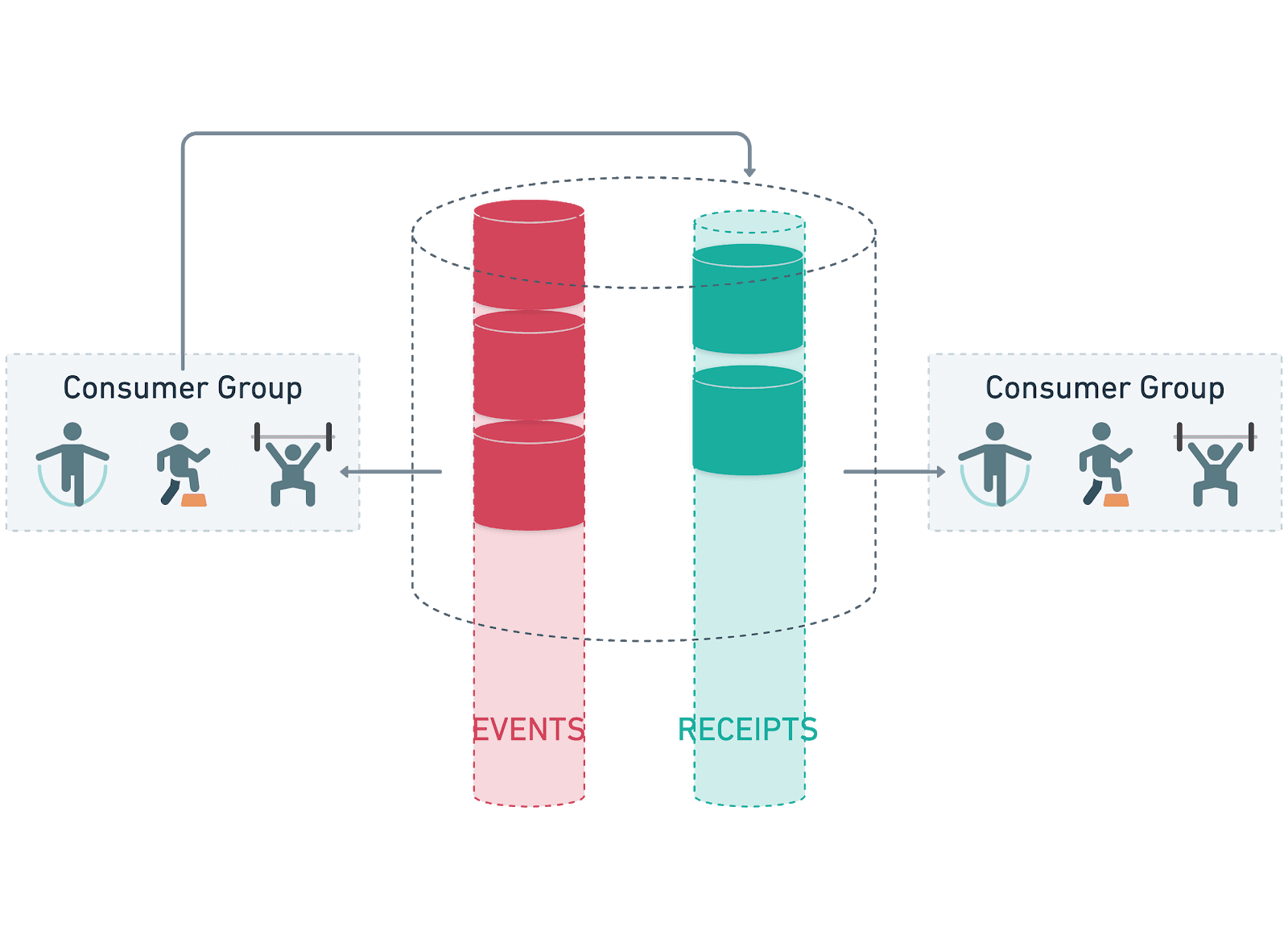
The following examples show the process after AdsDax has tracked a payable event and submitted the message to our queue ready for consumption (for the sake of brevity we’ve skipped over the part where adverts get served to the device, an advert displays, etc). We start with the messages being added to the events topic like so:
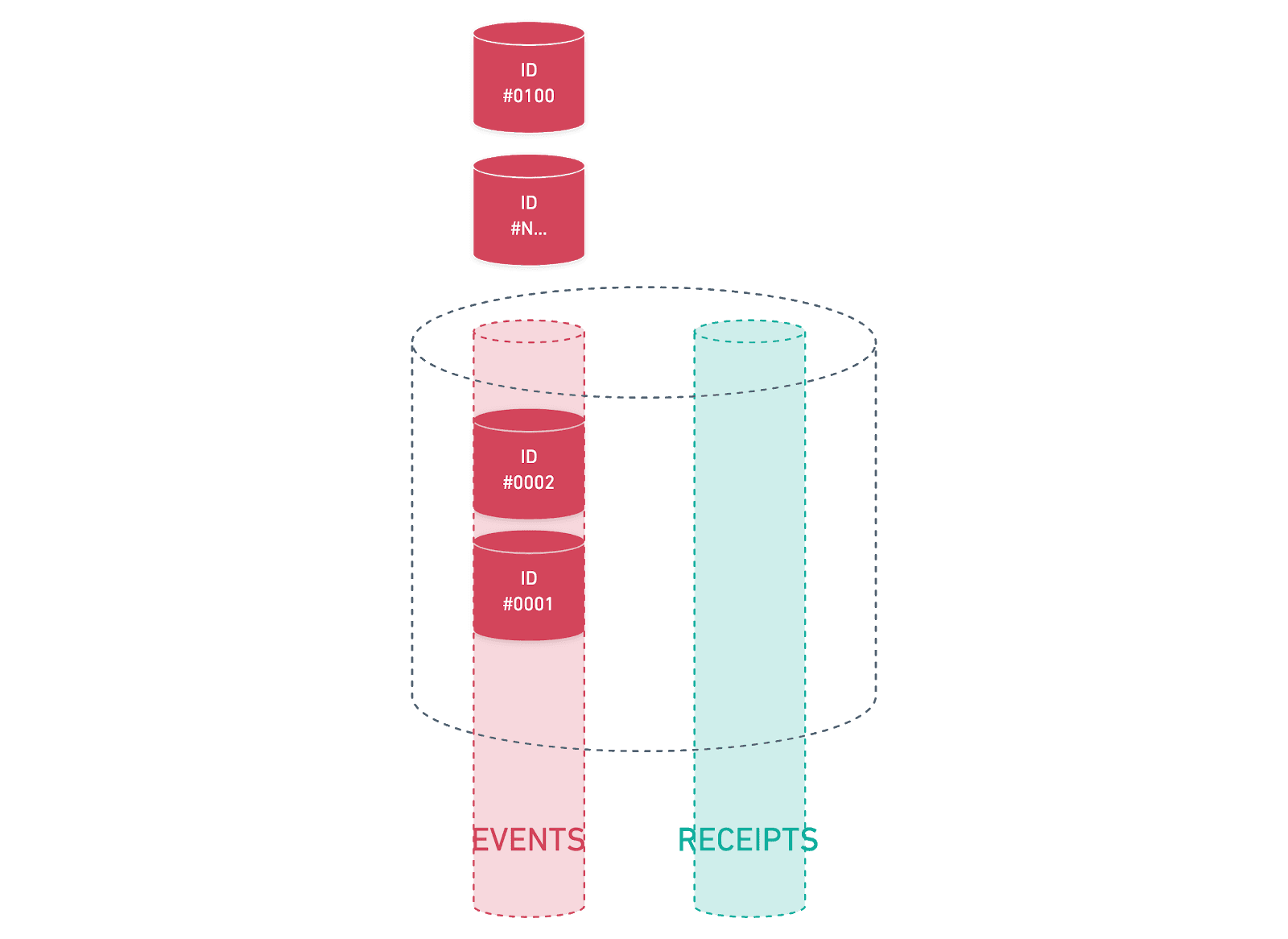
As messages are submitted they are all given a unique identifier within the queue service. Messages are consumed on a first-in, first-out basis, which means that even if for some reason there is a delay in processing them, they are still processed fairly. In this example, we’ve added 100 messages to the events topic ready to be processed. As the event messages are added, they are processed by a group of consumers monitoring that topic for activity. In the AdsDax events consumer group, we are currently using 10 consumers, however we can control this number as necessary, increasing if we find a consistent delay in messages being processed, or reducing the number in order to be more efficient if messages are few and far between.
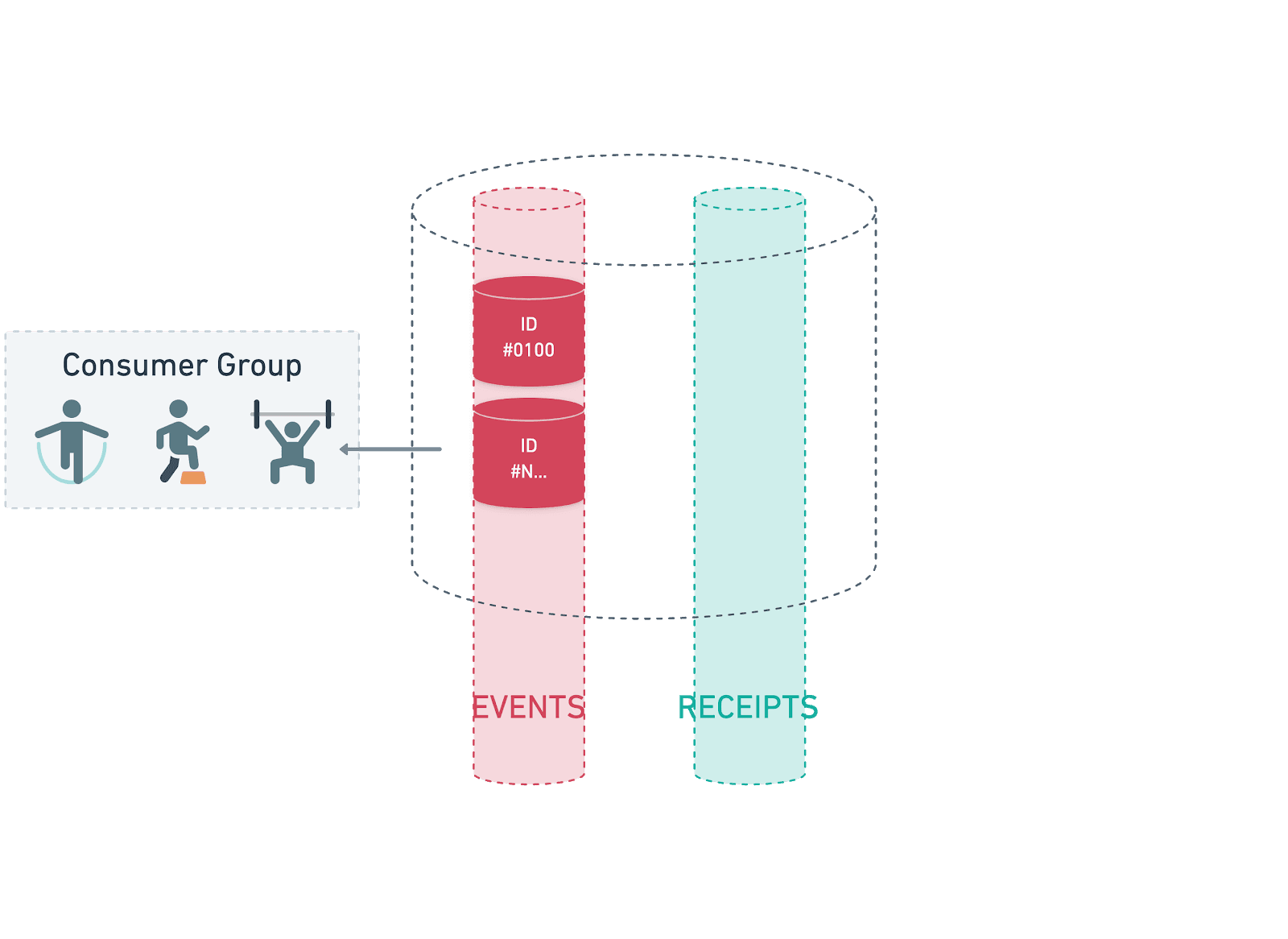
The event consumers process and package events into transactions, creating a log of the events in the transaction bundle. We create small bundles of events rather than submit them all individually as we find this provides a nice balance between cost reduction and ease of management (not having to create hundreds of consumers to deal with the events). During our previous experimentation with other ledger platforms that use less secure, more inefficient consensus algorithms such as Federated Byzantine Agreement, it was also a necessity due to the lack of scale available within the platform. Once the events have been bundled, the consumers submit the transaction to the mainnet, spread across a large amount of the mainnet nodes. This means that should there be an issue with a particular node or geographic region, at least some of our consumers should remain in touch with the network. Assuming we don’t encounter any pre-check errors and can connect to the Hedera network, the event consumers then turn into producers, creating messages with the transaction ID and event bundle in the receipts topic.
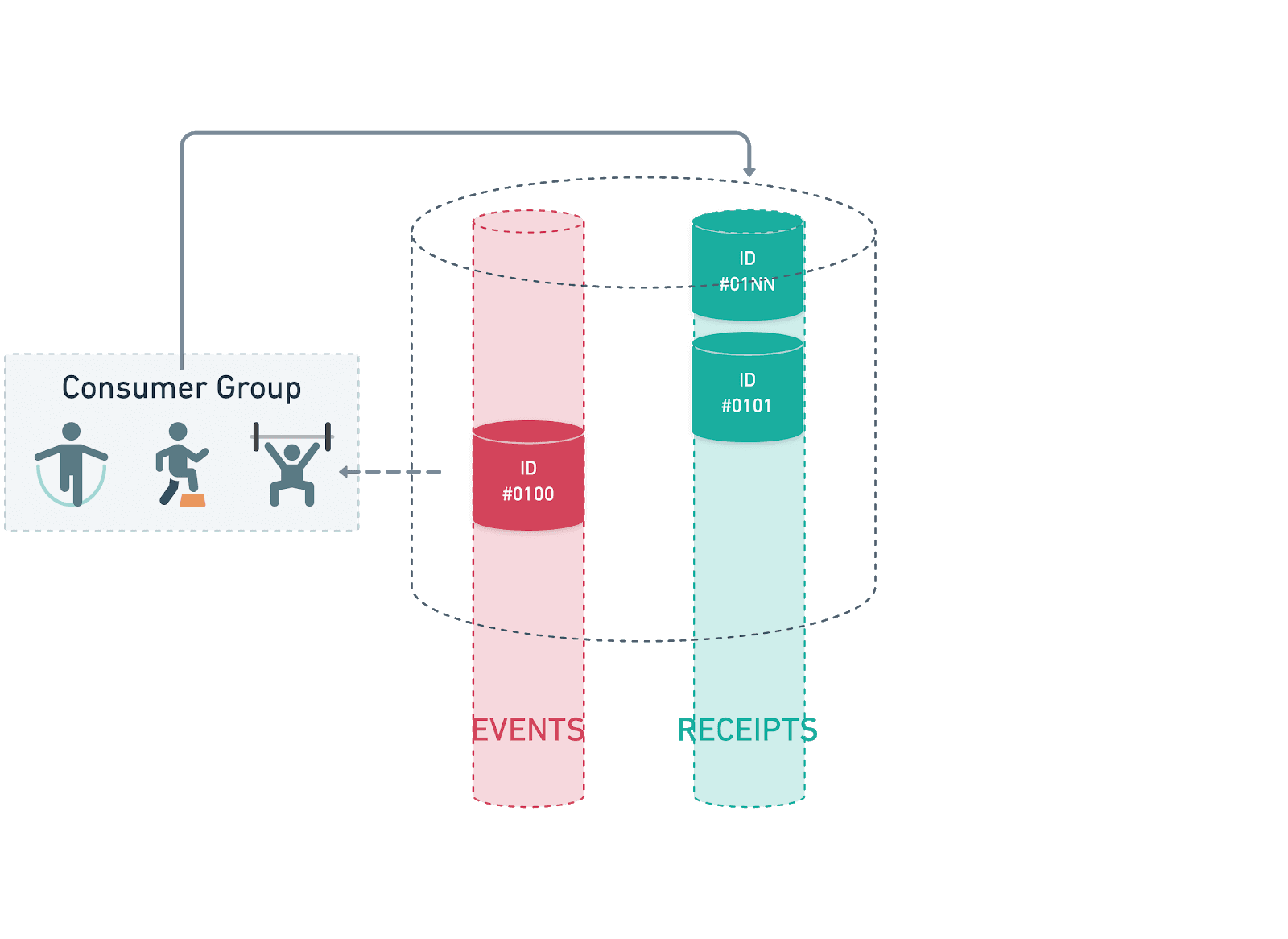
We maintain separate consumer groups for receipt messages and event messages, which allows us to factor in any performance differences in both the application logic being used as well as any network delays. In order to reduce the amount of wasted work, when receipt messages are added they are set with a 10 second delay so that consensus should already have been reached when we first check the status. This is an improvement over our previous incarnation on another ledger platform, where the network maintained an open connection whilst submitting a transaction until consensus had been reached or enough rounds had passed for the transaction to fail.
The 10 second delay happens in the background, so as to not stop the consumers from processing messages. Once a receipt message is in the ready state and available for consumption, the consumer reserves it, unpacks the message payload including the transaction ID and the event bundle, and checks the network to see the status of the transaction.
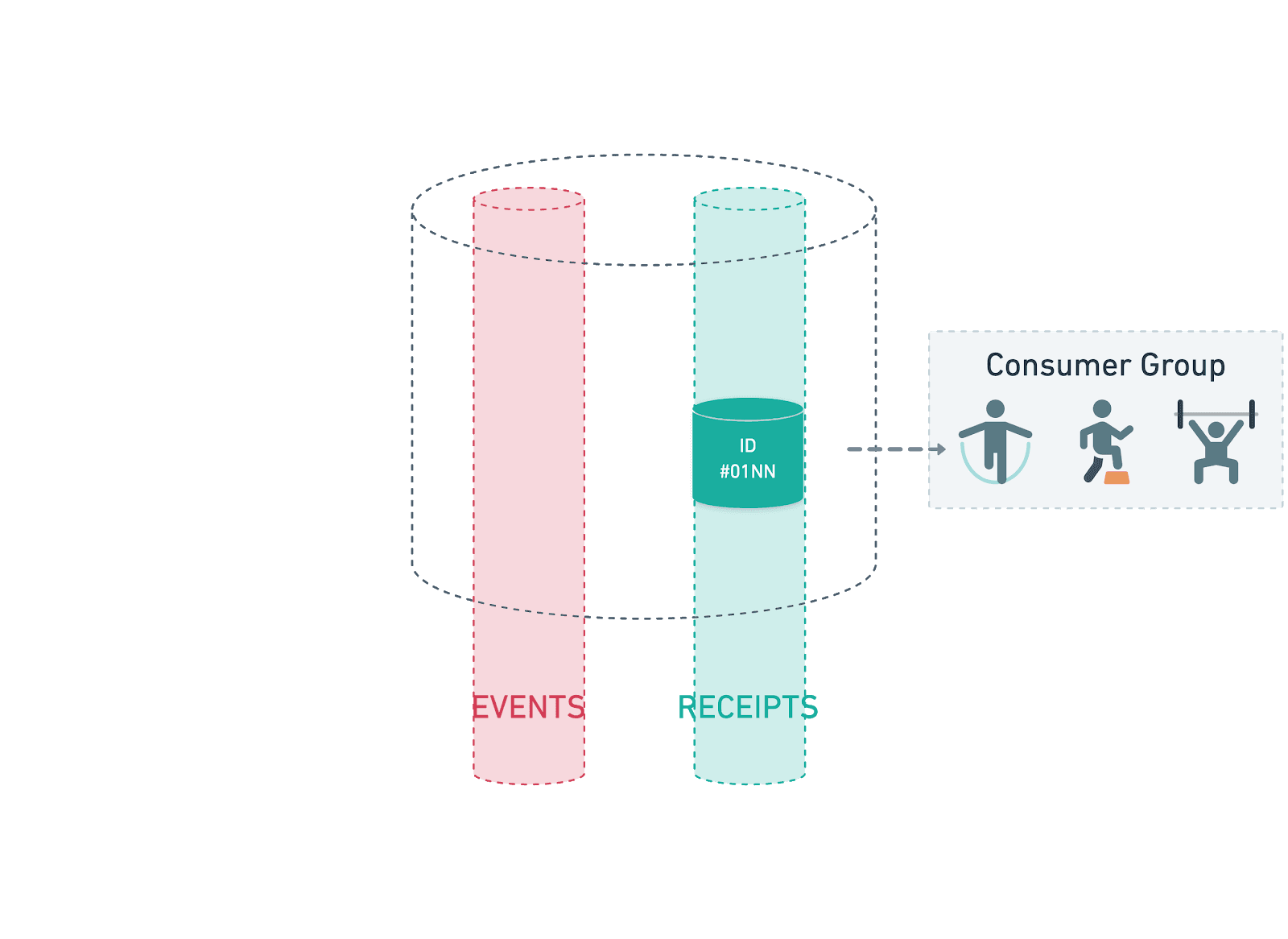
If for some reason the transaction hasn’t reached consensus, we release the job on another 10 second delay in order to check again, repeating this process for up to 3 minutes until the transaction receipt will have been discarded by the mainnet. After this, or assuming there is any other non-SUCCESS status, we bury the message with any additional information so that it can be manually inspected and the transaction status inspected on the mirrornet.
We also use the Hedera mirrornet if the transaction receipt shows the SUCCESS status, as we then use it to retrieve the full transaction details with the transaction record. This helps to both further reduce our costs and also helps to reduce load on the mainnet. Once we have all of the required information, the transaction ID, event bundle and transaction record information is then all logged ready to share with our advertising partners. This then helps to provide transparency to our advertisers who can then use the information to compare with their own records, as well as checking Hedera Hashgraph explorers to validate the transactions took place.
This process then continually repeats as more adverts get delivered and more events are tracked.
Hedera Hashgraph and Beanstalkd Code Examples
As mentioned, one benefit we gain from using a message service is that it decouples our existing applications, which are mostly PHP based, from the Go based applications which interact with the Hedera Hashgraph network. Whilst some aspects of our existing platform utilise Apache Kafka as a message queue, our initial experimentation with distributed ledgers led us to using a spare Beanstalk [https://github.com/beanstalkd/beanstalkd] instance we had set up so that if we had any issues they would be isolated and wouldn’t affect the rest of our platform .
Whilst Beanstalk isn’t quite as performant as Kafka, it is useful as a development tool as it is simple, fast and efficient, has wide language support and doesn’t have many dependencies to install or manage (for instance, you don’t need to set up and support Zookeeper as you might with Kafka).
If you are using composer in your PHP projects, you can include the Beanstalk PHP client Pheanstalk [https://github.com/pheanstalk/pheanstalk, other clients are available] in your application by including it in the require section of your composer.json file:

"require": {
"pda/pheanstalk": "4.0.*",
// other dependencies
}
Once you have included it, connecting to a Beanstalk instance and creating a message is a simple process. Our messages use JSON formatting so we can set a “type”, with the consumers then using different logic to handle different job types, with a data field containing information relevant to the job (in our case it would be data about the event being tracked):
$pheanstalk = Pheanstalk::create('127.0.0.1') // connect to the beanstalk instance
// "put" your message on the queue
$pheanstalk
->useTube('events')
->put(json_encode(['type' => 'event', 'data' => #eventData]) // We can also set options like priority, delay and the maximum runtime of the consumer
After we have submitted the message to our Beanstalk queue in our PHP tracking application, we then use our Go based consumers to watch for the job (our consumers are managed using Supervisor process control, however that is probably beyond the scope of this post) and handle the data associated with it. The below shows a simplified example of the setup logic we use to interact with the Hedera Hashgraph network:
// Import the Beanstalk package and the Hedera Go SDK
import (
"github.com/beanstalkd/go-beanstalk"
"github.com/launchbadge/hedera-sdk-go"
// other imports
)
// Connect to our Beanstalk instance
beanstalkConnection.error := beanstalk.Dial("tcp", "127.0.0.1:11300")
if error != nil {
panic(error)
}
// Listen to the appropriate tube(s)/topic(s)
tubes := []string{"events", "second_tube", "other_tube"}
tubeSet := beanstalk.NewTubeSet(beanstalkConnection, tubes...)
If you aren’t already familiar with message queues some of the processes may seem a little strange at first, so it is important to understand the lifecycle of a message, and how it gets passed through the system. The below diagram outlines how messages may circulate between different states:
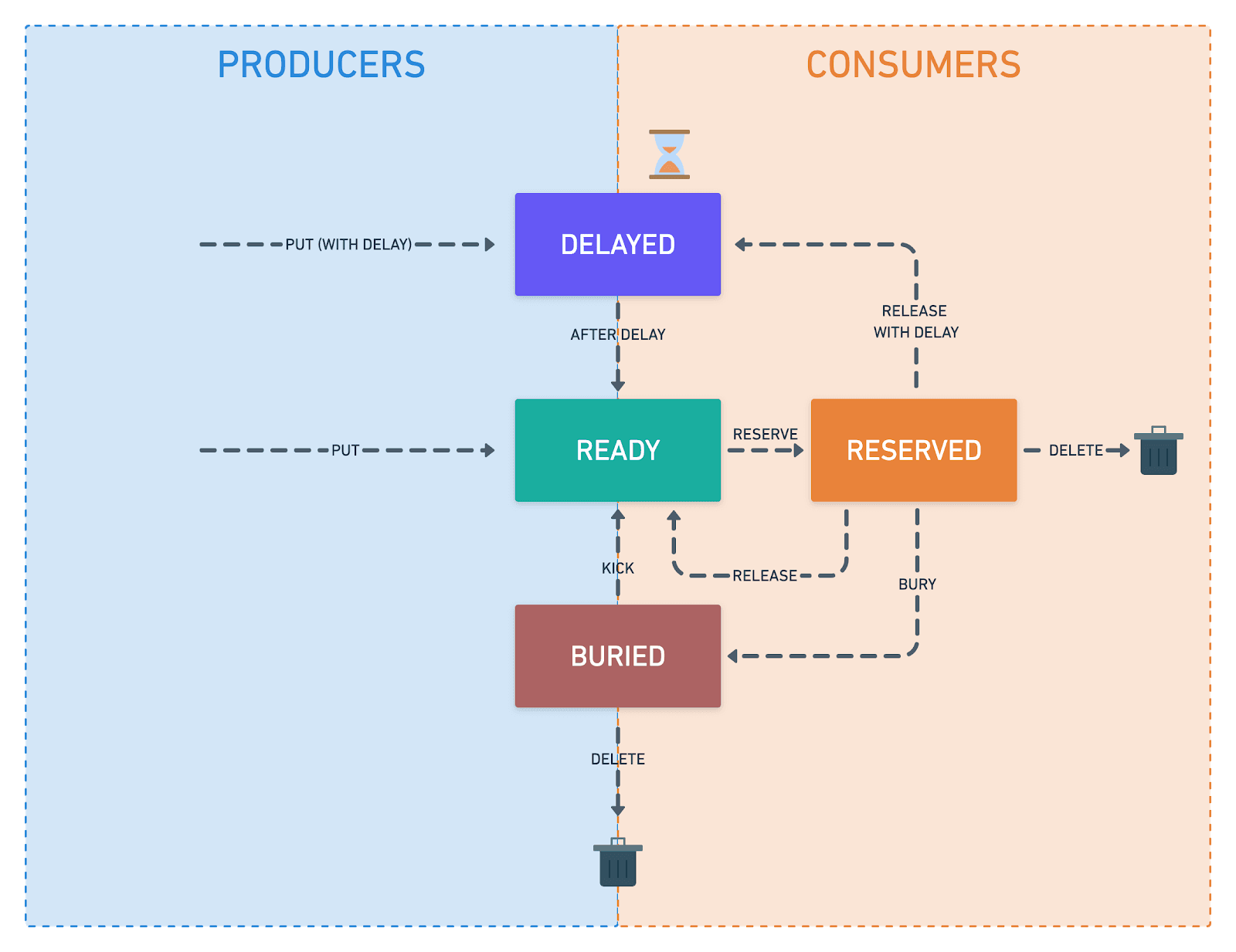
Taking our tracking application as an example producer, you can see that usually a producer will put a message into the system (optionally with a delay), and then they will disconnect. Depending on your application logic, in some cases you may want your consumers to also produce messages, which we do by having our event consumers produce receipt check messages (we separate these by using different topics, or tubes in Beanstalk).
Unless they are already processing a message, most of the time your consumers will be watching a tube waiting for a message to become ready, which means it is available for processing. The consumer will then reserve the job, which stops any other consumers in the group from processing the same message. Assuming the message is processed successfully, it can then be deleted and removed from the system, which is the process most messages follow (put – – – > READY – – – > reserve – – – > RESERVED – – – > delete).
In certain circumstances, however, you may want to adjust how the message is processed. For example, when checking the Hedera mainnet for a receipt, if consensus has not yet been reached (the network returns UNKNOWN status), we will release the message with a 10 second delay to stop any consumers from processing it until it returns to the READY state. As previously mentioned, if we still cannot resolve the status of the transaction after the 3 minute receipt window has expired, we bury the job where it can be manually inspected and compared to mirrornet data.
As we want our consumers to resume processing between one message and the next, we create a loop in the Go code, within which we add the code to reserve and handle messages:
//Begin our loop
for {
//will wait for up to an hour before dying
messageId, messageBody, error := tubeSet.Reserve(3600 * time.Second)
if error != nil {
panic(error)
}
messageString := string(messageBody)
//we use the gjson package (github.com/tidwall/gjson) to simplify working with the messages at this point,
// however depending on your data you could unmarshall it into a Go struct if you prefer
messageType := gjson.Get(messageString, "type").String()
messageData := gjson.Get(messageString, "data").String()
switch messageType {
case "event":
//call the function or run the logic to handle any EVENT messages
case "receipt":
//call the function or run the logic to handle any RECEIPT messages
default:
//example error handling to bury the unknown message (uses the built in “fmt” package)
fmt.Printf("Unable to match message with ID %v and type %v to a known type. Burying the message.n", messageId, messageType)
error = beanstalkConnection.Bury(id) //could instead call beanstalkConnection.Delete(messageId)
if error != nil {
panic(error)
}
}
}
Checking Records using the MirrorNet
One side effect of processing a lot of transactions is that there is also a lot of valuable data on the network we need to retrieve so that we can share it with our advertising partners. To do this directly on the Hedera mainnet would not only add load unnecessarily, it also becomes quite expensive fairly quickly. As it costs $1 USD to retrieve 10,000 records, to obtain the records for all of the transactions we have submitted would cost over $1600 USD. Instead, we can easily reduce both costs and load on the mainnet by turning to the Hedera’s network of mirror nodes.
We are able to do this thanks to the team at OpenCrowd, who have given access to their DragonGlass APIs so that Hedera developers can utilise the detailed information they collect about every transaction and contract call on Hedera Hashgraph. Also, whilst mainnet nodes typically only store records for up to 24 hours, DragonGlass provides historical records of network activity dating back prior to Hedera reaching Open Access.
In order to utilise their information in your application, first you need to sign up to get an access key for their API here [https://app.dragonglass.me/hedera/apiview], where you can also view the documentation for their various APIs.
Once you have your access key, it is simply a case of replacing any record calls you are currently sending to the mainnet with calls to the DragonGlass API, like so:
// NOTE: FOR THE SAKE OF BREVITY SOME ERROR CHECKING AND HANDLING HAS BEEN REMOVED!!!
// import the net/http package to send network requests and regexp package for formatting the transaction ID
import (
"net/http",
“regexp”
//other includes
)
//add some variables to be used throughout your application
var dragonglassAccessKey = "Y0ur-ACc3s5-K3y..."
var httpClient = http.Client{}
//other application code such as sending a transaction, and checking the receipt to see if consensus has been reached.
// Assuming the receipt is returned successfully, send a request to DragonGlass API to get the record.
// First, we need to format the transactionID (0.0.12345@1234567890.123456789)
// into just the numerical characters (00123451234567890123456789)
regex, error := regexp.Compile("[^0-9]+")
formattedTransactionId := regex.ReplaceAllString(transactionId, "")
// create the network request
request, error := http.NewRequest("GET", "https://api.dragonglass.me/hedera/api/transactions/" + formattedTransactionId, nil)
// if you want to get the extra information recorded by DragonGlass,
// replace the URL with the following to instead view the raw transaction data: “https://api.dragonglass.me/hedera/api/transactions/raw?transactionRecordID=” + formattedTransactionId
// add the “x-api-key” header so we can access the DragonGlass API
request.Header.Set("x-api-key", dragonglassAccessKey)
//send the request to DragonGlass
response, error := httpClient.Do(request)
// get the response body as bytes, and then convert to a string
responseBytes, error := ioutil.ReadAll(response.Body)
responseString:= string(responseBytes)
// responseString is now a string representation of the DragonGlass API response JSON.
// You can create structs to unmarshall this data or use the gjson package to retrieve data
recordData := gjson.Get(responseString, "data.0").String() //get the first data entry as a string (some APIs return multiple entries)
// now get any of the information you wish to collect, such as the consensus timestamp consensusTimestamp = gjson.Get(recordData, "consensusTime").String()
What next?
This post highlights some of the methods we’ve used to both process transactions at a high frequency as well as ensure we are as economically efficient as possible. We are still hard at work building towards our ultimate vision of a fair advertising exchange that rewards all participants. We are also looking forward to utilising some of the new tools and services being built by both the team at Hedera Hashgraph and other developers in the community, such as the Hedera Consensus Service.
At AdsDax, the advertising partners we have spoken to are excited by having not only the current scale and security offered by our platform (and the Hashgraph algorithm), but also the ability to even further customise both what and how we track to ensure they are getting true value for their money. The team at AdsDax are looking forward to furthering our Hedera Hashgraph integration and leveraging this technology to create new and exciting applications to track digital events and reward consumers for their online actions.


